
什么是回归分析
回归分析是一种描述变量间关系的统计分析方法,通过建立数学模型来探索信息中的规律性。在现代机器学习中,回归分析扮演着至关重要的角色。
在线教育场景中,我们可以将课程满意度作为因变量Y,而将平台交互性、教学资源质量和课程设计作为自变量X。凭借回归分析,大家能够量化这些因素对学生满意度的具体影响程度。
回归分析本质上是一种预测性建模技术,重要用于预测分析。哪怕预测结果多为连续值,但它也能够用于预测离散值甚至二值结果。
线性回归:简单却强大
找到最能匹配数据的截距和斜率。就是线性回归是回归分析中最基础的形式,它假设因变量和自变量之间存在线性关系。这种关系的直观表现可以用一条直线来刻画,而线性回归的目的就
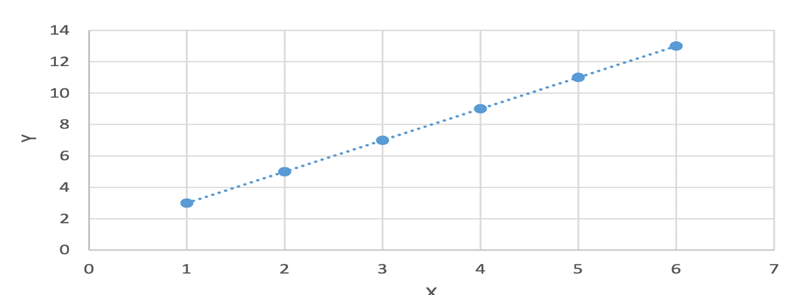
在某些情况下,变量间的线性关系是确定性的,比如当X取值1、2、3、4、5、6时,Y对应取值3、5、7、9、11、13。然而在实际应用中,变量间通常只是近似的线性关系,这就需要我们找到一条能够最好地解释数据的直线。
如何拟合数据
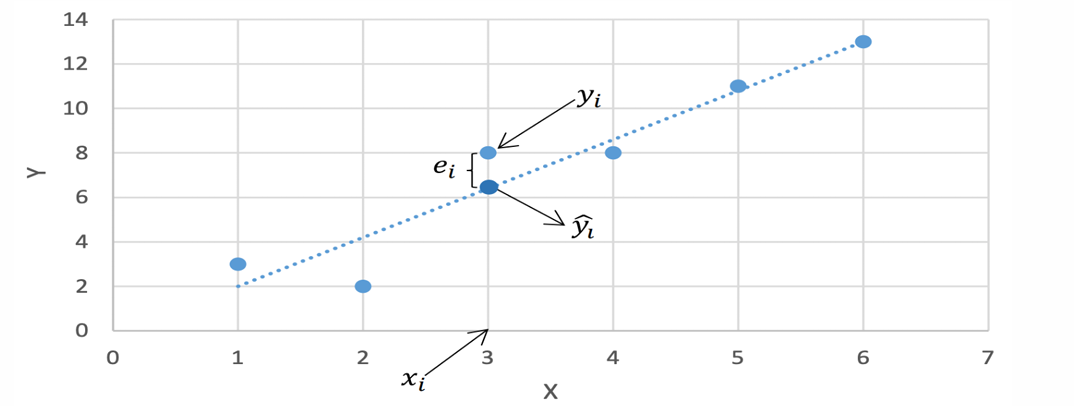
目标:得到一条直线使得对于所有训练样例的误差项尽可能小
线性回归的基本假设
为了确保线性回归模型的有效性,我们需要满足以下四个核心假设:
线性关系假设:自变量与因变量间存在线性关系
独立性假设:数据点之间相互独立
无共线性假设:自变量之间无高度相关性,相互独立
正态性假设:残差独立、等方差,且符合正态分布
这些假设是线性回归模型成立的基础,在实际应用中需要通过各种统计检验来验证这些假设是否得到满足。
损失函数:衡量模型好坏的标准
在回归分析中,损失函数用于量化预测值与真实值之间的差异。常见的损失函数包括:
然而最常用的是基于误差平方和的损失函数,因为它具有良好的数学性质且便于优化。
minb1,b2∑i=1nei2=∑i=1n(yi−y^i)2=∑i=1n(yi−b1−b2xi)2\begin{aligned}\min_{b_{1}, b_{2}} \sum_{i=1}^{n} e_{i}^{2} &= \sum_{i=1}^{n} (y_{i} - \hat{y}_{i})^{2} \\&= \sum_{i=1}^{n} (y_{i} - b_{1} - b_{2} x_{i})^{2}\end{aligned}b1,b2mini=1∑nei2=i=1∑n(yi−y^i)2=i=1∑n(yi−b1−b2xi)2
最小二乘法:求解最优参数
最小二乘法是一种凸优化方法,用于求解最优的截距和斜率参数。通过最小化误差平方和,我们可以得到最佳的参数估计值。
具体求解过程中,我们需要计算自变量和因变量的均值,然后通过公式计算斜率参数。此种方法保证了我们得到的解是全局最优解,而非局部最优。
对误差平方和分别求偏导并令其为零:
∂∑i=1nei2∂b1=−2∑i=1n(yi−b1−b2xi)=0(1)\frac{\partial \sum_{i=1}^{n} e_{i}^{2}}{\partial b_{1}} = -2\sum_{i=1}^{n} \left(y_{i}-b_{1}-b_{2} x_{i}\right) = 0 \tag{1}∂b1∂∑i=1nei2=−2i=1∑n(yi−b1−b2xi)=0(1)
∂∑i=1nei2∂b2=−2∑i=1nxi(yi−b1−b2xi)=0(2)\frac{\partial \sum_{i=1}^{n} e_{i}^{2}}{\partial b_{2}} = -2\sum_{i=1}^{n} x_{i}\left(y_{i}-b_{1}-b_{2} x_{i}\right) = 0 \tag{2}∂b2∂∑i=1nei2=−2i=1∑nxi(yi−b1−b2xi)=0(2)
参数估计解
求解上述正规方程组得到回归系数估计量:
b2=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2b_{2} = \frac{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}}b2=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
b1=yˉ−b2xˉb_{1} = \bar{y} - b_{2}\bar{x}b1=yˉ−b2xˉ
其中:
梯度下降法:迭代优化的艺术
除了最小二乘法,梯度下降法给出了另一种参数求解途径。这种途径经过迭代更新参数值,逐步逼近最优解。
沿着损失函数的负梯度方向更新参数。初始化参数值后,重复以下步骤直到收敛:计算梯度,然后按照学习率调整参数值。就是梯度下降法的核心思想
算法步骤
简单示例:
import numpy as np
# 生成模拟数据
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) # 真实关系: y = 4 + 3x + 噪声
# 初始化参数 (对应您图片中的 b1, b2,这里我们用 w 和 b)
w = np.random.randn(1) # 权重,可以理解为b1
b = np.zeros(1) # 偏置,可以理解为b2
# 设置超参数
learning_rate = 0.1 # 学习率 α
n_iterations = 1000 # 最大迭代次数
# 梯度下降开始
for i in range(n_iterations):
# 1. 计算预测值
y_pred = w * X + b
# 2. 计算损失(MSE),用于监控
loss = np.mean((y_pred - y)**2)
if i % 100 == 0:
print(f"Iteration {i}: Loss = {loss:.4f}")
# 3. 计算梯度!(这是图片中缺失的关键步骤)
# 损失函数 J 对 w 的偏导数
dw = (2 / len(X)) * np.sum((y_pred - y) * X)
# 损失函数 J 对 b 的偏导数
db = (2 / len(X)) * np.sum(y_pred - y)
# 4. 同时更新参数 w 和 b!(对应图片中的更新步骤,但补全了梯度项)
w = w - learning_rate * dw
b = b - learning_rate * db
# 输出最终结果
print(f"\n训练完成!")
print(f"真实函数: y = 4 + 3 * x")
print(f"学习到的函数: y = {b[0]:.4f} + {w[0]:.4f} * x")执行结果:
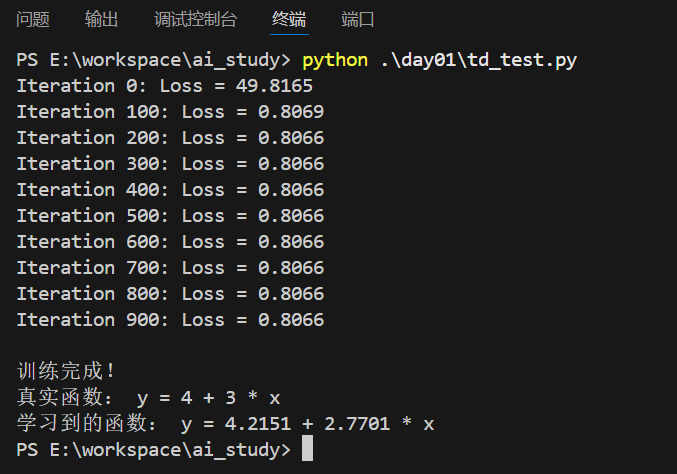
这种方法特别适用于大规模数据集和在线学习场景,因为它可以逐样本更新模型参数。
多元线性回归:处理复杂关系
当因变量有多个时,我们需使用多元线性回归。这时矩阵表示法就显得格外重要。

多元线性回归的矩阵表示为:Y=Xβ+ϵ
参数估计的推导(法一)
此时误差项向量e定义为真实值y 与预测值 Xβ 的差值:
e=
e1e2⋮en
=y−Xβe = \begin{bmatrix}e_{1} \\ e_{2} \\ \vdots \\ e_{n}\end{bmatrix} = y - X \betae=e1e2⋮en=y−Xβ
损失函数定义为所有误差项的平方和(Sum of Squared Errors, SSE),它可以简洁地用向量转置表示为:
∑i=1nei2=e′e\sum_{i=1}^{n} e_{i}^{2} = e'ei=1∑nei2=e′e
(其中 e′e'e′ 表示向量 eee 的转置)
求解最小二乘估计
为了找到使损失函数最小的参数β\betaβ,我们对其求导并令导数为零:
∂e′e∂β=−2X′Y+2X′Xβ=0\frac{\partial e' e}{\partial \beta} = -2 X' Y + 2 X' X \beta = 0∂β∂e′e=−2X′Y+2X′Xβ=0
解析解(正规方程)
通过求解上述方程,可以得到参数β\betaβ的最优解,即著名的正规方程:
β=(X′X)−1X′Y\beta = (X' X)^{-1} X' Yβ=(X′X)−1X′Y
其中Y是因变量向量,X是自变量矩阵,β是系数向量,ε是误差项。基于此种表示,损失函数可以写为误差平方和的形式。
通过求解正规方程,大家可以得到系数的最优估计:β=(X′X)−1X′Y
参数估计的推导(法二)
1. 问题定义与目标
用一组参数 β0,β1,…,βk\beta_0, \beta_1, \dots, \beta_kβ0,β1,…,βk来拟合因变量yyy,模型形式如下:
yi=β0+β1xi1+β2xi2+⋯+βkxik+ϵiy_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_k x_{ik} + \epsilon_iyi=β0+β1xi1+β2xi2+⋯+βkxik+ϵi
其中:
模型的预测值为:
y^i=β0+β1xi1+β2xi2+⋯+βkxik\hat{y}_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_k x_{ik}y^i=β0+β1xi1+β2xi2+⋯+βkxik
第 iii个观测的残差eie_iei为真实值与预测值之差:
ei=yi−y^i=yi−(β0+β1xi1+⋯+βkxik)e_i = y_i - \hat{y}_i = y_i - (\beta_0 + \beta_1 x_{i1} + \dots + \beta_k x_{ik})ei=yi−y^i=yi−(β0+β1xi1+⋯+βkxik)
2. 目标函数:残差平方和(SSE)
普通最小二乘法的目标是找到一组参数β\betaβ,使得所有观测的残差平方和最小。残差平方和定义为:
∑i=1nei2=∑i=1n(yi−β0−β1xi1−⋯−βkxik)2\sum_{i=1}^{n} e_{i}^{2} = \sum_{i=1}^{n} (y_{i} - \beta_{0} - \beta_{1} x_{i1} - \dots - \beta_{k} x_{ik})^{2}i=1∑nei2=i=1∑n(yi−β0−β1xi1−⋯−βkxik)2
目标:最小化 SSE(β0,β1,…,βk)\text{SSE}(\beta_0, \beta_1, \dots, \beta_k)SSE(β0,β1,…,βk)。
3. 求解方法:对参数求偏导并令其为0
为了找到最小值点,我们对目标函数(SSE)分别关于每个参数βj\beta_jβj求偏导数,并令其等于零。这会得到一个由k+1k+1k+1个方程组成的方程组(正规方程组)。
偏导过程
方程组总结:
∑(yi−β0−β1xi1−⋯−βkxik)=0∑(yi−β0−β1xi1−⋯−βkxik)xi1=0⋯∑(yi−β0−β1xi1−⋯−βkxik)xik=0\begin{array}{l}\sum (y_{i} - \beta_{0} - \beta_{1} x_{i1} - \dots - \beta_{k} x_{ik}) = 0 \\\sum (y_{i} - \beta_{0} - \beta_{1} x_{i1} - \dots - \beta_{k} x_{ik}) x_{i1} = 0 \\\cdots \\\sum (y_{i} - \beta_{0} - \beta_{1} x_{i1} - \dots - \beta_{k} x_{ik}) x_{ik} = 0\end{array}∑(yi−β0−β1xi1−⋯−βkxik)=0∑(yi−β0−β1xi1−⋯−βkxik)xi1=0⋯∑(yi−β0−β1xi1−⋯−βkxik)xik=0
4. 转化为矩阵形式
为了更简洁地求解,我们将上述方程组用矩阵表示。
定义矩阵和向量:
此时,残差平方和可以写为:
SSE=eTe=(y−Xβ)T(y−Xβ) SSE = e^Te = (y - X\beta)^T(y - X\beta)SSE=eTe=(y−Xβ)T(y−Xβ)
对方程组 ∑eixij=0\sum e_i x_{ij} = 0∑eixij=0(对于所有 jjj,包括 xi0=1x_{i0}=1xi0=1)进行矩阵化,等价于:
XTe=0 X^T e = 0XTe=0
将 e=y−Xβe = y - X\betae=y−Xβ 代入上式:
XT(y−Xβ)=0 X^T (y - X\beta) = 0XT(y−Xβ)=0
这被称为正规方程。
5. 推导解析解(闭式解)
由正规方程出发:
XTy−XTXβ=0 X^T y - X^T X \beta = 0XTy−XTXβ=0
移项得:
XTXβ=XTy X^T X \beta = X^T yXTXβ=XTy
最后,假设 XTXX^T XXTX是可逆的(即满秩),我们在等式两边左乘其逆矩阵(XTX)−1(X^T X)^{-1}(XTX)−1,即可得到参数向量β\betaβ的最小二乘估计量:
β=(XTX)−1XTy \beta = (X^T X)^{-1} X^T yβ=(XTX)−1XTy
以“误差平方和”为损失函数的优缺点同时也伴随着一些缺点损失函数对于超过和低于真实值的预测是等价的模型评估:相关系数与决定系数
为了评估回归模型的质量,我们引入两个重要指标:
1. 相关系数r:衡量因变量和自变量之间的线性相关程度,计算公式基于协方差和标准差。
r=1n−1∑i=1n(xi−xˉsx)(yi−yˉsy) r = \frac{1}{n - 1} \sum_{i = 1}^{n} \left( \frac{x_{i} - \bar{x}}{s_{x}} \right) \left( \frac{y_{i} - \bar{y}}{s_{y}} \right)r=n−11i=1∑n(sxxi−xˉ)(syyi−yˉ)
其中:
标准差的计算公式:
sx=1n−1∑(xi−xˉ)2 s_x = \sqrt{\frac{1}{n - 1} \sum (x_i - \bar{x})^2}sx=n−11∑(xi−xˉ)2
2. 决定系数R²:也称为判定系数或拟合优度,计算公式为:
R2=1−∑i(yi−y^i)2∑i(yi−yˉ)2 R^{2} = 1 - \frac{\sum_{i} (y_{i} - \hat{y}_{i})^{2}}{\sum_{i} (y_{i} - \bar{y})^{2}}R2=1−∑i(yi−yˉ)2∑i(yi−y^i)2
等价形式
R2=1−∑i(yi−y^i)2/n∑i(yi−yˉ)2/n=1−MSEVAR R^{2} = 1 - \frac{\sum_{i} (y_{i} - \hat{y}_{i})^{2}/n}{\sum_{i} (y_{i} - \bar{y})^{2}/n} = 1 - \frac{MSE}{VAR}R2=1−∑i(yi−yˉ)2/n∑i(yi−y^i)2/n=1−VARMSE
变量说明:
重要性质与注意事项
决定系数的取值范围
与相关系数的关系
重要区分:R2R^2R2不是相关系数rrr 的平方
统计意义解释
核心解释
R2R^2R2 衡量了回归模型对数据的解释程度,具体来说:
yyy的波动有多少百分比能够被xxx的波动所描述
数值含义
总结:R2R^2R2是一个主要的回归诊断工具,但需要谨慎解读,避免将统计相关性误解为因果关系。
决定系数衡量了模型对数据变动的解释程度,表示y的波动有多少百分比能被x的波动所描述。R²越接近1,表示自变量对因变量的解释越好。
但必须特别注意:变量相关并不等于存在因果关系。这是一个在解释回归分析结果时频繁被忽视的主要原则。
总结
回归分析作为描述变量间关系的统计分析技巧,在机器学习中占有重要地位。从简单线性回归到多元线性回归,从最小二乘法到梯度下降法,回归分析提供了丰富的工具箱来处理各种预测挑战。
经过相关系数和决定系数,我们可以量化评估模型性能,但同时也要警惕相关性与因果关系的区别。回归分析不仅是一个技术工具,更是一种资料思维的方式,帮助我们从数据中发现规律,做出更科学的决策。
无论是学术研究还是商业应用,掌握回归分析都是素材科学家的必备技能。随着大数据时代的到来,回归分析的价值将会更加凸显。