
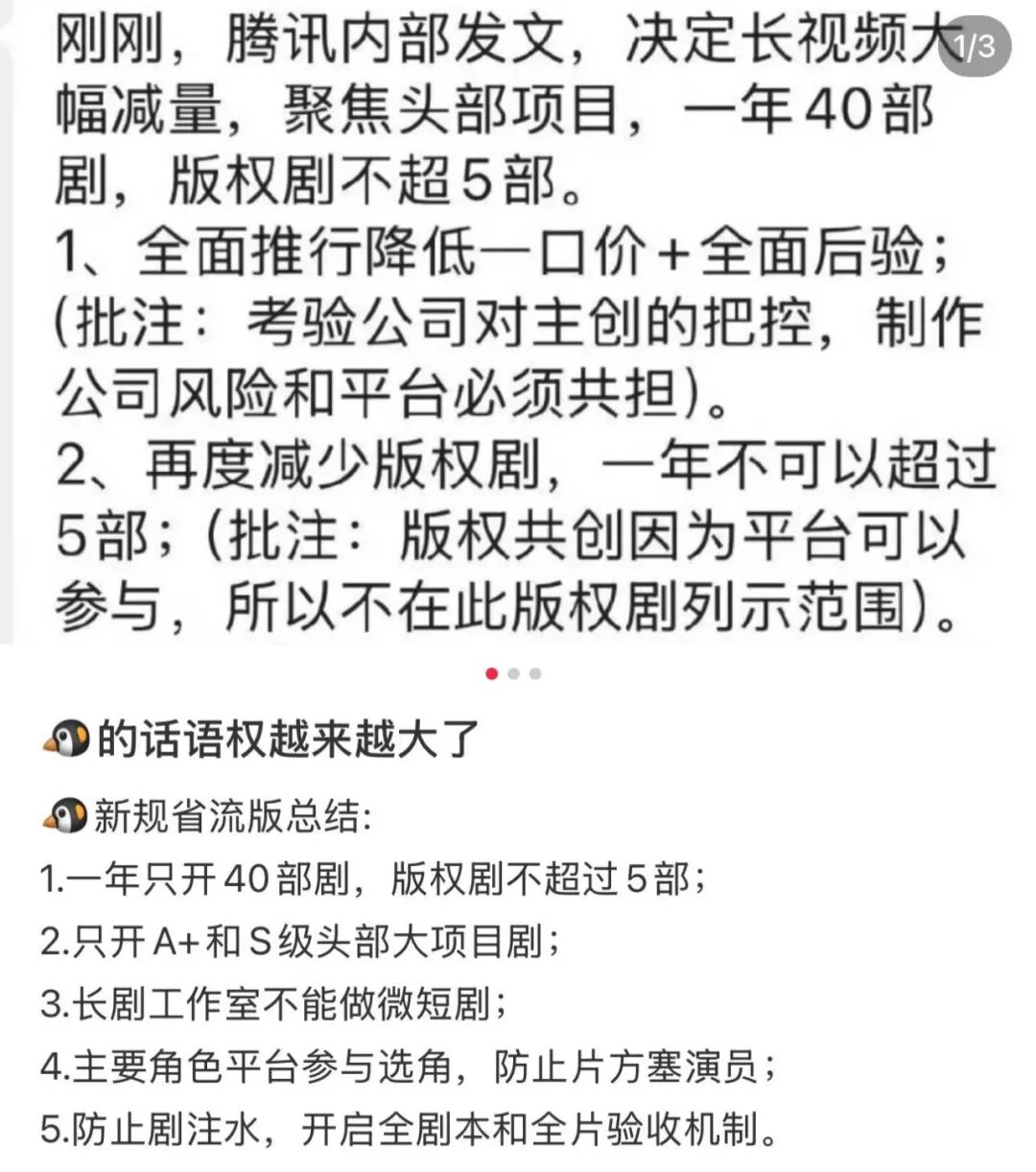
2023年起,视频平台全面调整内容结构,减少外部版权采购,增加自制与定制剧比例。据业内不完全统计,2024年爱优腾芒的外采剧数量同比减少约45%,版权剧成交价普遍下降。
影视公司在选购IP时,不再依靠编辑判断,而更多依据平台榜单和数据表现。收藏量、评论量成为评估作品潜力的关键指标。对于网络文学平台而言,这意味着数据表现与版权交易被直接绑定。
晋江文学城、长佩文学等平台的版权业务在2025年明显降温。以晋江为例,尽管平台整体收入从2020年的10.36亿元增长至2024年的14.4亿元,但版权授权项目的成交量自2024年底起下降明显。今年上半年,长篇小说改编交易数量同比减少近三分之一,单个作品授权价也出现普遍下滑。
影视市场的收缩,逼迫网文平台寻找新的增长叙事,而榜单的数据繁荣成了最直观的手段。通过制造热度、拉高数据,平台可以向版权方展示一种仍具潜力的假象。

这种数字泡沫也改变了内容筛选的逻辑。影视公司在采买IP时,往往要求提供有多少收藏、多少评论、多少热搜等数据证明,于是平台在版权招商阶段便主动优化数据,以满足对方指标。
事实上,这种“优化”并非直接伪造,而是可以通过算法推荐、活动拉新等方式集中提升目标作品的数据表现。一些普通水准的作品被包装成“准爆款”,进入改编谈判名单亦是常态。
这么做的后果是编辑在评估作品潜力时难以区分真实热度与系统推力,影视方在采购时也无法准确预估市场反馈。最终受损的还是内容本身。2024年多部由爆款小说改编的剧集表现不佳,恰恰反映出“数据≠受众”的尴尬现实。
谁还在为虚假的数据买单?
当“数据”取代“内容”,网络文学生态的结构性问题也开始显现。注水数据带来的连锁反应,不仅破坏了市场判断,也在悄然重塑创作模式。
首先,创作趋同肯定会愈发严重。平台算法偏好能带来高互动的数据标签,如“霸道总裁”“复仇重生”“赘婿逆袭”等题材权重不断上升。要想要自己的小说数据好,创作者不得不被引向同一条路径,写已有“成功模式”的故事,创新则成了高风险选项。

其次是作者群体的流失正在加剧。随着曝光机会被数据主导,新人作者几乎难以突围。根据网络文学研究中心的统计,2019年后入行的职业作者留存率不足10%,多数人在一年半内因收入不稳、读者积累困难而退出。中腰部作者群体的萎缩,头部作品集中垄断曝光,腰部和尾部几乎无人问津,平台内容结构断层明显。
曾经充满试验性的网络文学,如今越来越像一个固定流水线。
读者的信任危机也在同步发生。榜单曾是他们发现新作品的重要渠道,如今却成为广告展示区。收藏量高、评论稀少的作品屡见不鲜,导致用户对平台推荐系统的信任度下降。越来越多读者转向独立社区、书评博主或社交媒体寻找推荐,而非依赖平台榜单。这种迁移趋势意味着,平台正在失去内容主导权。
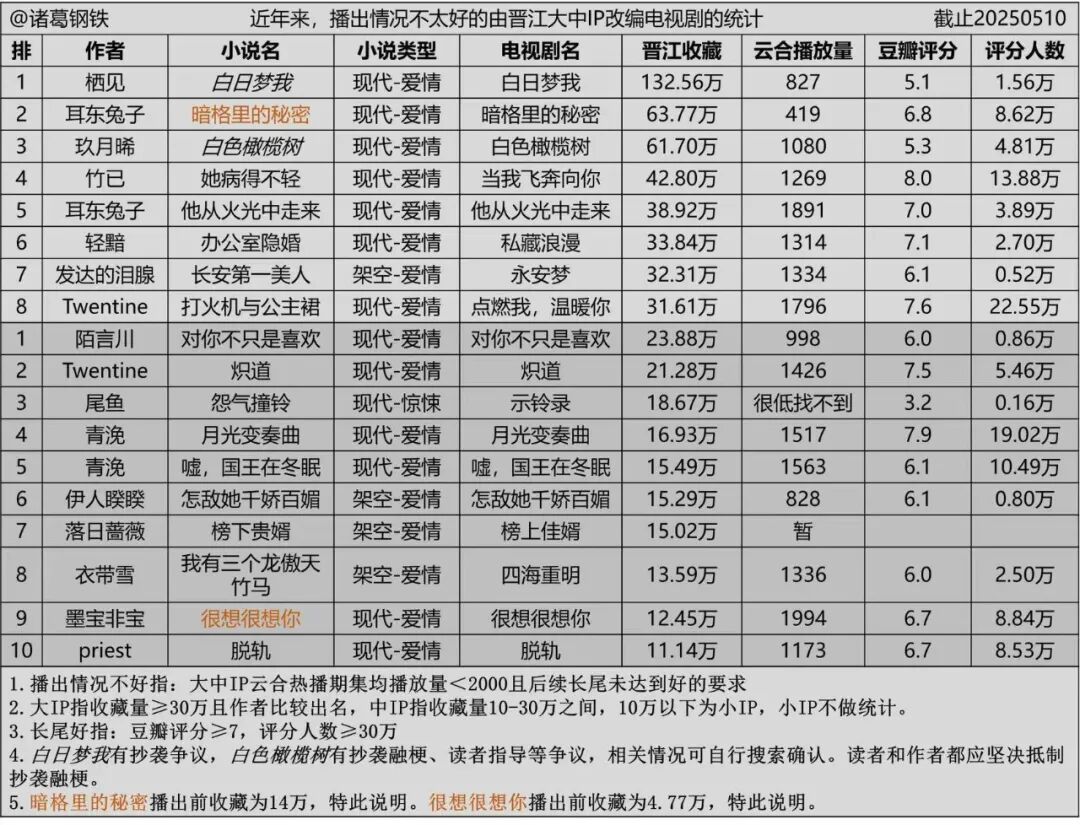
而对于产业链上游来说,影视公司在采购过程中不断发现,许多所谓“百万收藏”的作品并没有相匹配的真实读者群,改编后流量与预期严重不符,资本的信任度也会逐步下降,使得版权交易更加谨慎,甚至趋于冻结。平台为了维持吸引力,又不得不进一步“优化数据”,最终形成恶性循环。
网络文学从诞生以来,始终以自由、平等和想象力为核心价值。它曾是草根写作者展现创造力的舞台,也是影视工业的重要内容源头。但当行业被数据逻辑主导,创作自由被压缩,内容同质化严重,原有的创新土壤也在流失。如今,真正有潜力的故事往往出现在在小众平台、独立作者群体中,他们的读者数量不大,却具有更高的忠诚度和传播力。
回到开头的疑问,谁在制造“注水”网文?
答案或许是整个体系都在参与。平台需要热度维持商业模式,作者需要数字获取机会,版权方需要榜单判断价值。每一方都在推动泡沫继续膨胀。而真正能打破循环的,或许不是监管,也不是算法革新,而是行业重新建立对“内容价值”的共识。
只有让作品的热度回归读者选择,网络文学或许才能重新找到平衡,留下的将是那些真正能被记住的故事。毕竟,对一个行业而言,真正的繁荣从不在榜单上,而在那些仍然愿意认真创作、认真反馈的人身上。