
一般来说,在python学习爬虫的过程中,建议大家都会去爬一遍豆瓣电影网站,去获取电影名字、电影评分、主演、评论之类的数据。
因为这个豆瓣电影网站是一个近乎完美的爬虫练习场所,首先这个网站拥有非常丰富的电影数据,网页的结构非常规范清晰,反爬虫措施十分温和,不需要登陆账号,也没有验证码,但是也又一定的难度,在新手爬虫技能不多的情况下正好能爬。
先说一下爬豆瓣电影网站的三个步骤:
第一步:导入相关模块,比如requests模块和BeautifulSoup模块
import requests
from bs4 import BeautifulSoup
第二步:使用requests模块请求信息并返回网页信息
url="https://movie.douban.com/cinema/nowplaying/guangzhou/"
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.\
0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"}
request=requests.get(url,headers=headers)
request.encoding="utf-8"
这里我添加了一个headers,它叫伪装头,将爬虫程序伪装成浏览器。
伪装头不是手输入的,而是从浏览器里面复制的,鼠标右键点开审查元素,再点击Network,发现是空白的,刷新网页后会出现信息,如下图,
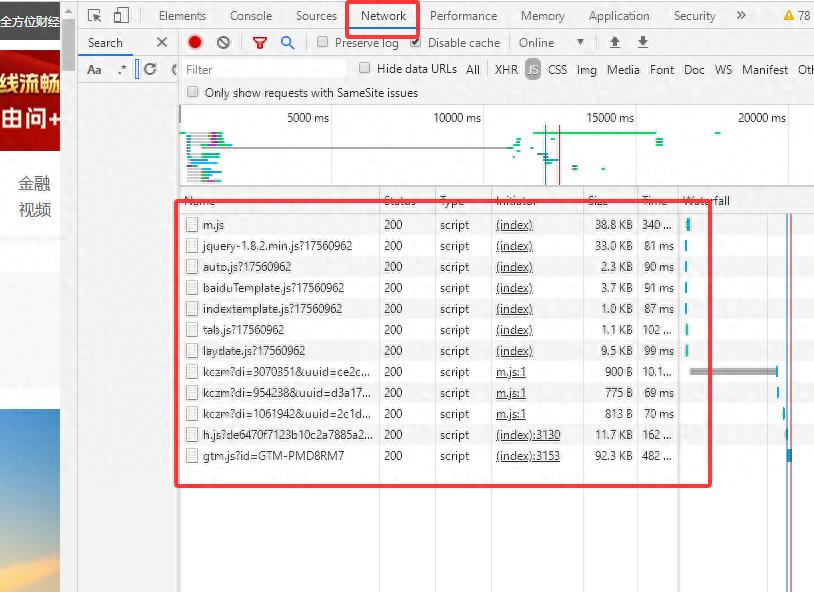
然后在红色大框内随便选一个鼠标左边单击,会出现hearders信息
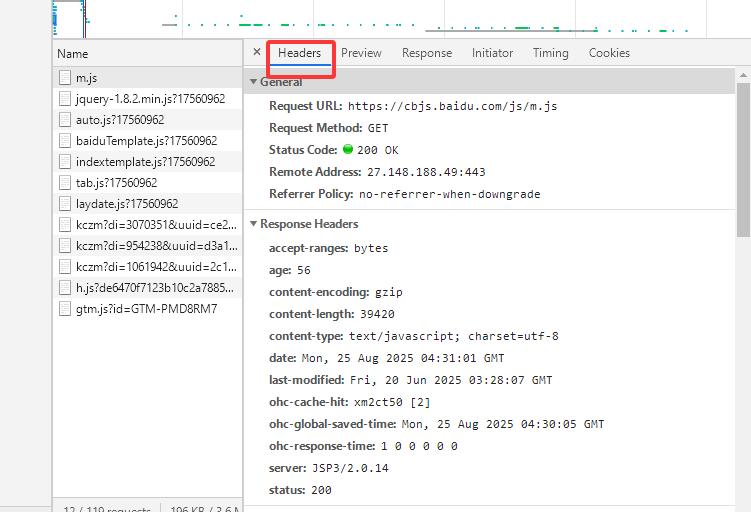
我们需要的是headers里面的user-agent(用户代理)信息,它再headers页面的最下面,将信息复制下来,构造成一个字典数据,然后赋值给hearders。
(要注意的是这里Mozilla/5.0的前面一般会有个空格占位,需要删除空格,不然会出错)
{“user-agent”:“Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0”}
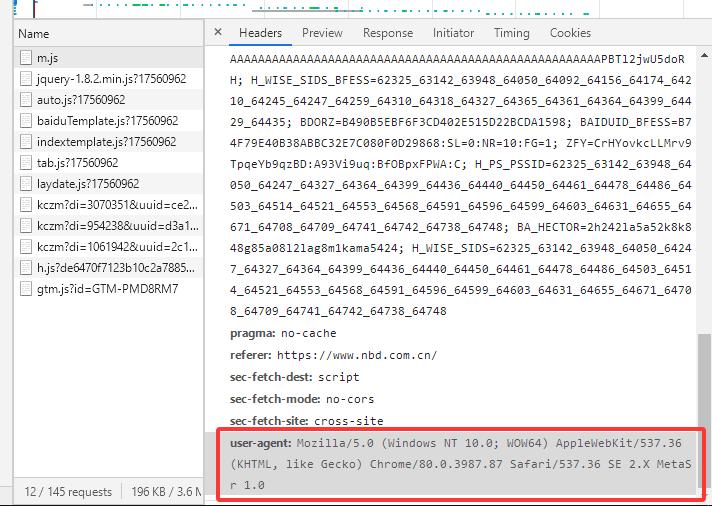
构造好请求头后,获取信息是要将请求头放在requests.get(url,headers=headers)里面,这样请求信息时豆瓣网站才会认为爬虫时浏览器,请求信息返回后通过request.encoding=“utf-8”将乱码还原成正常网页,第二步就完成了。
提醒一下:headers=headers的含义并不是两者相等,左边的headers只是一个标识符(名称),右边的headers里面有一个字典,两者之间的等号是将右边headers的字典赋值给左边的headers,类似于a=1。
第三步:使用BeautifulSoup模块,解析网页并输出信息
#这一步是正常的解析网页,将第二步的request.text网页信息通过BeautifulSoupl的xml解析
soup=BeautifulSoup(request.text,"lxml")
#通过find()限定电影信息的大范围,再用find_all()限定小范围。
movie_main=soup.find("ul",class_="lists").find_all("li",class_="list-item")

#构造一个空列表movies,用来放置爬取的信息
movies=
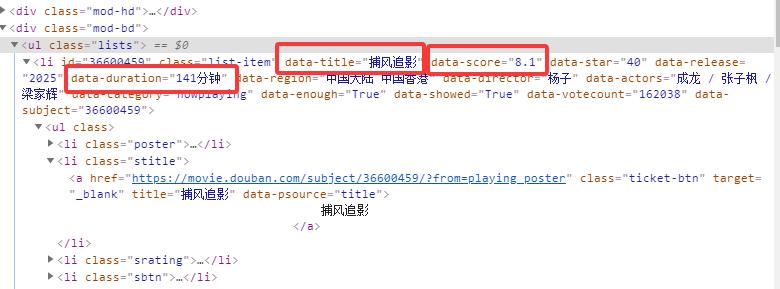
”“”还是for循环,和find_all()基本是配套使用的,find_all()返回的数据类型是列表,从列表中的每一个值值获取信息,这里使用的是get()函数,get意思是获取,这个函数的作用是获取被复制标识符的信息,比如电影名称”捕风追影“,它的左边有一个等号,等号左边是data-title,
data-title=”捕风追影“,我们想获取电影名称,用get()函数获取标识符data-title就得到了电影名称。同理,“data_score”=“评分”,”data_duration“=”时长“ “”“
for movie in movie_main:
data_title=movie.get("data-title") #电影名称
data_score=movie.get("data-score") #电影评分
data_duration=movie.get("data-duration") #电影时长
“”“append.()之前提过是列表增加值的方法,movies.append()是将值添加进刚才创建的空列表movies。
提醒一下:列表内的值不仅仅是字符串和数字,它也可以是列表和字典,下面这个步骤就是给空列表增加了一个字典。{"电影":data_title,"评分":data_score,"时长":data_duration}
movies.append({"电影":data_title, "评分":data_score, "时长":data_duration})
print(movies)
输出信息可以看一下,列表movies的每一个值都是字典,字典内包含电影名、评分和市场的信息
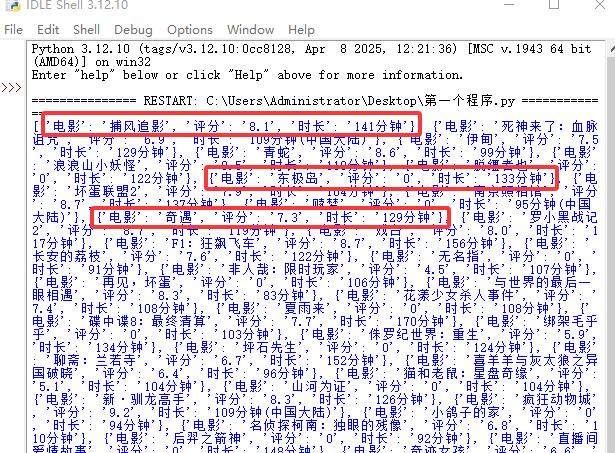
上面三个步骤已经将需要的信息获得了,如果想获取更多信息,可以再for循环里面继续添加主演、国家之类的信息。
如果你觉得只是从输出界面显示不好看,可以将上面的信息保存再csv文件里。
csv是python的一个内置模块,无需下载,只需要提前导入模块即可。
简单介绍一下csv文件,它类似于excel文件,表格界面,能够像excel一样编辑,该有的功能都有,优点是存储信息的能力非常强,读取和写入速度快,缺点编辑后无法保存,一旦关闭后会恢复成原始数据,所以再csv文件编辑数据后一定要记得转成excel格式保存。
下面是第四个步骤:将获取的电影信息下载保存到csv文件中,
with open()是常见的读写文件合成语句,设定要保存文件的名字+格式,
mode="w":方式是写入
encoding="utf-8":指定编码方式是"utf-8"
newline="":保证下载到csv表格的数据没有空行
fieldnames=
"电影","评分","时长"
:这里构造了表格的表头
csv_dict_writer=csv.DictWriter(file,fieldnames=fieldnames):数据以字典的方式写入,同时将构造的表头赋值给fieldnames,fieldnames是关键字,意思是表头。
for row in movies :因为movies是一个列表,所以用for循环遍历每一个值
csv_dict_writer.writerow(row):csv_dict_writer是标识符(名称),writerow()是单行写入方法,因为有for循环,所以列表内的字典信息都会逐条写入csv文件内。
with open("豆瓣电影.csv",mode="w",encoding="utf-8",newline="") as file:
fieldnames=
"电影","评分","时长"
csv_dict_writer=csv.DictWriter(file,fieldnames=fieldnames)
csv_dict_writer.writeheader()
for row in movies:
csv_dict_writer.writerow(row)
print("最新上映电影信息获取成功!")
最后是print()函数,因为python的代码运行方式一般是从上到下,写这段的作用是提醒,代码已经运行结束。
下面附上源码图:
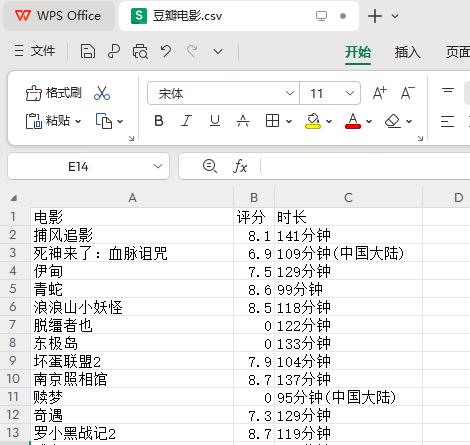
csv文件的下载图:有五十条信息,因为太长了所以只截图到这里。
总结一下:这一节主要是讲了如何从豆瓣电影网站获取最新上映电影信息,增加了伪装头概念,练习如何从网页内限定爬取信息的范围,新增get()函数,以及for循环函数的熟练使用,构造空列表和增加值的用法,还有下载保存文件的概念。
如果你能够看懂并独立使用上面的爬虫方式获取豆瓣网站的电影信息,恭喜你已经可以爬取大部分初级网站的文本信息,可以尝试爬取网站的评论之类的信息。